over(partition by class order by sroce) 按照sroce排序进行累计,order by是个默认的开窗函数,按照class分区。
2、开窗的窗口范围
over(order by sroce range between 5 preceding and 5 following):窗口范围为当前行数据幅度减5加5后的范围内的。 over(order by sroce rows between 5 preceding and 5 following):窗口范围为当前行前后各移动5行。
SELECT Regexp_Replace(Lower(Sys_Guid()),
'(.{2})(.{2})(.{2})(.{2})(.{2})(.{2})(.{2})(.{2})(.{4})',
'\4\3\2\1-\6\5-\8\7-\9-') AS Dummy
FROM Dual
CONNECT BY Rownum <= 20;
CREATE TABLE [dbo].[E_Sequence]([Sequence_ID] [int] IDENTITY(1,1) NOT NULL, CONSTRAINT [PK_E_Sequence] PRIMARY KEY CLUSTERED ([Sequence_ID] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]);
SET IDENTITY_INSERT [dbo].[E_Sequence] ON
INSERT INTO [dbo].[E_Sequence] (Sequence_ID)
SELECT number FROM [master]..[spt_values] WHERE type = 'P'
UNION ALL
SELECT number + 2048 FROM [master]..[spt_values] WHERE type = 'P'
SET IDENTITY_INSERT [dbo].[E_Sequence] OFF
那。。。这张序号表是干什么用的呢?看看下面就知道了:
SELECT Dateadd(day, Sequence_id, '2011-1-1') AS Class_Date FROM E_Sequence
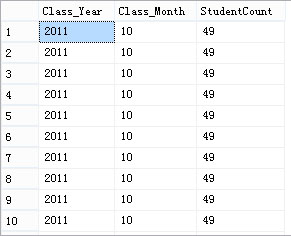
SELECT Year(Class_Date) AS Class_Year,
Month(Class_Date) AS Class_Month,
StudentCount
FROM (SELECT Dateadd(day, Sequence_id, '2011-1-1') AS Class_Date
FROM E_Sequence) t1,
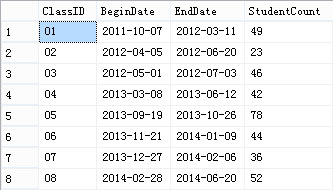
E_Classes t2
WHERE t1.Class_Date BETWEEN t2.BeginDate AND t2.EndDate
看看效果:
OK,这样,是不是就很明了了呢?“年”字段有了,“月”字段有了,“学生数”是不是就可以简单地加了?然后再一个行列转换就可以实现了(SQL2000请自行转为Case When End):
SELECT Class_Year AS ??,
Isnull([1], 0) AS ??,
Isnull([2], 0) AS ??,
Isnull([3], 0) AS ??,
Isnull([4], 0) AS ??,
Isnull([5], 0) AS ??,
Isnull([6], 0) AS ??,
Isnull([7], 0) AS ??,
Isnull([8], 0) AS ??,
Isnull([9], 0) AS ??,
Isnull([10], 0) AS ??,
Isnull([11], 0) AS ???,
Isnull([12], 0) AS ???
FROM (SELECT Year(Class_Date) AS Class_Year,
Month(Class_Date) AS Class_Month,
studentcount
FROM (SELECT Dateadd(day, Sequence_id, '2011-1-1') AS Class_Date
FROM E_Sequence) t1,
e_classes t2
WHERE t1.Class_Date BETWEEN t2.begindate AND t2.enddate) t
PIVOT (Sum(studentcount) FOR Class_Month IN
([1], [2], [3], [4], [5], [6], [7], [8], [9], [10], [11], [12])) tpivot
看到了吧?有时,引入一张外表,可以让我们的思路更清楚。
如果将
SELECT Dateadd(day, Sequence_id, '2011-1-1') AS Class_Date FROM E_Sequence
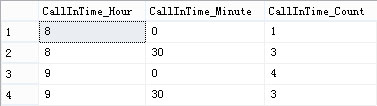
SELECT CallInTime_Hour,
CallInTime_Minute,
Count(*) AS CallInTime_Count
FROM (SELECT Datepart(HOUR, CallInTime) AS CallInTime_Hour,
Datepart(MINUTE, CallInTime) / 30 * 30 AS CallInTime_Minute
/*??SQL ??/??=?? ??????????*/
FROM [PerHalfHour]
WHERE CallInTime >= '2014-01-01'
AND CallInTime < '2014-01-02') t
GROUP BY CallInTime_Hour,
CallInTime_Minute
ORDER BY CallInTime_Hour,
CallInTime_Minute
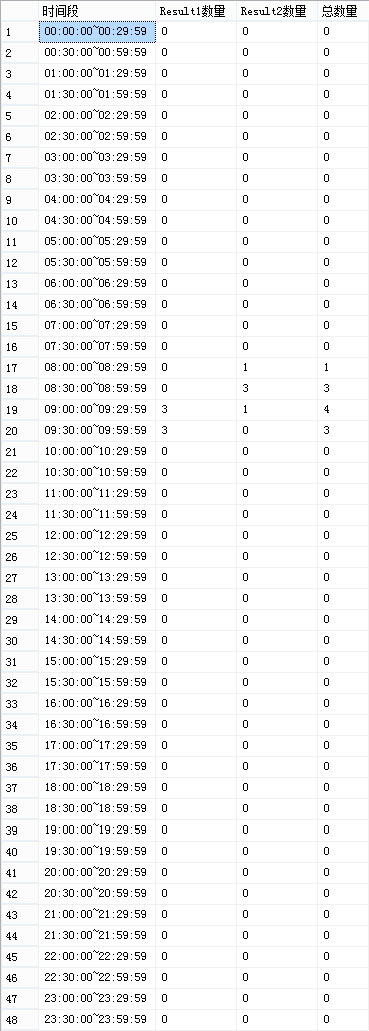
SELECT t0.sequence_time AS ???,
Isnull(CallInTime_Count, 0) AS ??
FROM sequence_halfhour t0
LEFT JOIN (SELECT CallInTime_Hour,
CallInTime_Minute,
Count(*) AS CallInTime_Count
FROM (SELECT Datepart(HOUR, CallInTime) AS CallInTime_Hour,
Datepart(MINUTE, CallInTime) / 30 * 30 AS CallInTime_Minute
/*??SQL ??/??=?? ??????????*/
FROM [PerHalfHour]
WHERE CallInTime >= '2014-01-01'
AND CallInTime < '2014-01-02') t
GROUP BY CallInTime_Hour,
CallInTime_Minute) t1
ON t0.sequence_hour = t1.CallInTime_Hour
AND t0.sequence_minute = t1.CallInTime_Minute